How AI Agent Skills Work and Why They Matter
There’s a common pattern when people build AI agents. They start with a short instruction. The agent works for the demo case. Then they add more rules. Then edge cases. Then a product catalog. Then a refund policy. Before long, the instruction is 8,000 tokens of tangled context, and the agent starts forgetting things because the model is drowning in text.
Skills fix this.
What skills are
A skill is a self-contained knowledge module that an agent loads only when it’s relevant. Instead of cramming everything into one instruction file, you break domain knowledge into separate pieces. Each piece has a name, a description of when it applies, and the actual content: step-by-step procedures, reference data, examples, edge case handling.
The agent sees the name and description of every installed skill at all times. That’s maybe 100 tokens per skill. When a user asks something that matches a skill’s domain, the agent pulls in the full content and follows it. When the conversation moves on, that context isn’t wasting space anymore.
It’s like giving someone a filing cabinet instead of making them memorize every document.
How they work at runtime
When your agent starts up, the runtime scans the .agent/skills/ directory and loads every skill’s metadata: its name and description. These get injected into the agent’s system prompt in an <available_skills> block, along with the file path to each skill.
When a user sends a message that matches a skill’s description, the agent reads the full skill file via the filesystem tool before doing anything else. That’s a hard rule in the system: if a matching skill exists, read it first. Don’t guess from general knowledge.
Some skills are marked as autoloaded. Those get their full content injected into the system prompt at startup, so the agent always has them. This is useful for skills that apply to almost every conversation, but it costs context space. Most skills should be on-demand.
The loading works in three tiers:
Tier one is metadata. Name and description, always present, about 100 tokens per skill. This is how the agent knows what’s available.
Tier two is the instruction body. The full content of the SKILL.md file, loaded when the agent activates the skill. Best kept under 5,000 tokens.
Tier three is reference material. Separate files in a references/ folder that the agent reads when it needs deeper detail. API documentation, format specifications, detailed examples. Loaded on demand within the skill, so even within an active skill, you’re not loading everything at once.
What a skill looks like
Each skill is a folder inside .agent/skills/ with a SKILL.md file:
.agent/skills/
└── refund-policy/
├── SKILL.md
├── references/
│ ├── refund-tiers.md
│ └── exception-cases.md
└── assets/
└── email-templates/The SKILL.md has YAML frontmatter and a markdown body:
---
name: refund-policy
description: "Handles customer refund requests. Use when the customer
asks about returns, refunds, cancellations, or money back. Covers
standard refunds, partial credits, and escalation rules."
metadata:
autoload: false
---
## Refund processing steps
1. Look up the customer's order in Stripe
2. Check if the order is within the 30-day return window
3. If the refund amount is under $500, process it directly
4. If over $500, surface it for team review with the order details
5. Send confirmation email using the template in assets/
## Standard refund tiers
See [refund tiers](references/refund-tiers.md) for amounts and
approval requirements by tier.
## Exceptions
Orders placed during promotional periods have different rules.
See [exception cases](references/exception-cases.md).The description field matters more than you’d think. It’s what the agent reads to decide whether this skill applies to the current question. A vague description means the agent won’t activate the skill when it should. A good description includes what the skill does, what words or topics should trigger it, and what use cases it covers.
Why not just put everything in the instruction
You can. Plenty of simple agents work fine with a single instruction file. But once you have five different workflows in one document, things get messy.
Language models have limited context windows, and even when the window is large, performance gets worse when there’s too much irrelevant text. An agent with ten skills loads only the ones it needs. An agent with everything in the instruction loads all of it, every time, even when 80% of it has nothing to do with the current question.
There’s also the maintenance problem. A 200-line instruction covering five workflows is hard to read and easy to break. You update the refund policy and accidentally change how billing questions work. With skills, each piece has clear boundaries. You can update one without touching the rest.
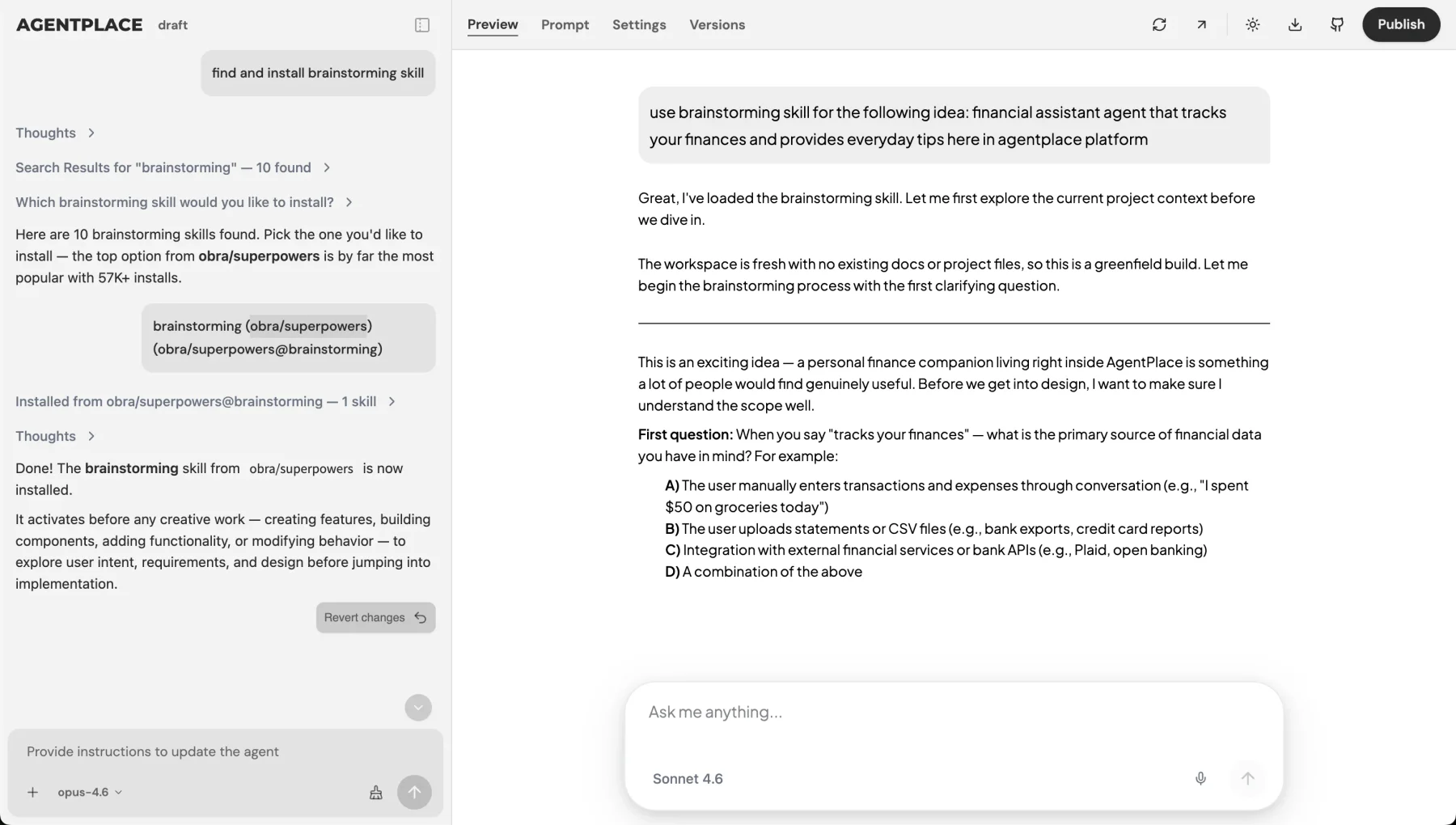
And skills can be shared. You can install one from GitHub or find one on skills.sh, the skill marketplace. If someone’s already built a skill for PDF processing or data analysis, there’s no reason to write it again. The builder can search and install them directly.
When to use autoload vs on-demand
Most skills should be on-demand. The agent loads them when it recognizes a relevant question, and the rest of the time they’re just a name and description in the background.
Autoload makes sense when a skill applies to nearly every conversation. If your agent is a customer support agent and every single interaction involves checking account status, a skill with account lookup procedures could be autoloaded. But if only 20% of conversations involve refunds, the refund skill should be on-demand.
The rule of thumb: if you’d feel comfortable saying “the agent needs this in every conversation,” autoload it. Otherwise, don’t.
How skills relate to other agent features
Skills are knowledge. They tell the agent how to think about a domain and what steps to follow. They don’t call APIs, render UI, or execute code.
MCP integrations are how the agent talks to external services. A skill might describe when and how to use a Stripe integration, but the MCP tool does the actual API call.
UI components are what the agent renders for the user. A skill might describe when to show a refund form, but the component is a separate piece of registered React code.
Backend tools handle server-side processing. A skill might describe a data analysis workflow, but the backend tool does the computation.
The instruction ties everything together. It defines the agent’s role, sets behavioral rules, and can include a Skills section that specifies priority rules when multiple skills apply, or override conditions for edge cases.
Building skills on Agentplace
You don’t have to write skills by hand. The builder agent can create them for you. Tell it “create a skill for handling warranty claims” and it writes the SKILL.md with the right frontmatter, organizes the content, and adds reference files if the domain is complex enough.
You can also install skills that already exist. skills.sh is a public marketplace where people publish skills for common tasks. The builder can search it, show you what’s available, and install directly. Skills are pulled from GitHub, so you can also point the builder at any public repo with a SKILL.md in it. The format is open: owner/repo for a whole repo as a skill, owner/repo@skill-name for a specific skill inside a repo, or a full GitHub URL. Once installed, skills land in .agent/skills/ with a lock file tracking the source and version. The builder can check for updates and pull new versions when they’re available.
If you want to write a skill manually, it’s a markdown file in a folder. No build step, no compilation. Drop the folder into .agent/skills/ and the agent picks it up on the next message.
Practical examples
A product catalog skill stores your product names, SKUs, pricing tiers, and availability rules. The agent loads it when a customer asks about products, so it can answer without calling an external API for static information. The instruction might have a summary, but the skill holds the full catalog with all the edge cases.
Compliance is a good use case for autoload. Your data handling policies, PII rules, and regulatory requirements go into a skill that’s always active. If a conversation touches sensitive data, the agent already has the procedures loaded.
A troubleshooting skill walks the agent through diagnostic steps. “Check if the user has restarted the device. Ask for the error code. Look it up in the reference table.” The references folder holds the error code table, which only gets loaded when the agent actually needs to look something up. The three-tier system means even within an active skill, you’re not burning context on a 500-row lookup table until the agent reaches for it.
Onboarding is a clean on-demand case. It covers account setup sequences, what information to collect, which systems to update via MCP, and what welcome message to send. Only applies to first-time users, so there’s no reason for it to take up space in every other conversation.
Getting started with skills
If you’re building on Agentplace, skills are available out of the box. Tell the builder what domain knowledge your agent needs, and it will create skills with the right structure. Browse skills.sh for pre-built ones, or point the builder at a GitHub repo with a skill you want to install.
Start with your agent’s most complex workflow. If the instruction for it is longer than a screenful of text, it’s a good candidate for a skill. Pull it out, give it a clear description, and let the agent load it when it’s needed. The instruction gets shorter, the context stays clean, and the agent still has access to everything.
Ready to deploy AI agents that actually work?
Agentplace helps you find, evaluate, and deploy the right AI agents for your specific business needs.
Get Started Free →